Building a Hierarchical Agent for Scheduling
Published on March 27, 2025
Everyone’s building agents, but not many people are writing clearly about how to implement them. This post walks through how I built a hierarchical agent architecture to solve a real problem: workforce scheduling with lots of messy constraints. I’ll cover why one-shot prompting didn’t work, how I ended up with an Orchestrator + child agents setup, and some practical lessons from getting it working. If you’re already deep into agent design, skip ahead to the architecture section — that’s the core of the post.
My project
I was working on workforce scheduling — basically, assigning staff to shifts under a variety of hard and soft constraints (availability, skills, legal rules, preferences, cost, etc.). It's a problem that’s annoying for managers but relatively easy to validate post-hoc, which makes it a great candidate for AI. This framework: hard to do, easy to validate is the most useful one I know for identifying areas to apply language models. My goal: given a blank schedule, can an AI fill it in a way that satisfies hard constraints and optimizes soft ones?
My first approach
My first attempt was to try and one-shot this task, and I wrote an entire custom eval report about the performance of different models at solving this problem for different schedule sizes, with different prompts, etc. The problems with that approach were manyfold:
It was only considering hard constraints
It tapped out at ~100 shifts, and only Claude-3.(5/6)-sonnet could do that reliably at the time. Since then, o1-pro (but not o1 or o3-mini-high), Claude-3.7-sonnet-thinking and recently, Gemini-2.5-pro have pushed that closer to 200 shifts, but this is still too limiting
It was expensive, because you needed to use frontier models to get enough accuracy (I expect this will change for a given level of performance given the rapidly falling price/performance of LLMs)
After hitting limitations with a one-shot approach, I started digging into agent-based methods
Agents 101
Most readers here know what an agent is: an LLM that can use tools, reason about intermediate steps, and act iteratively. The most common pattern is ReAct — Reasoning + Action — where the model generates thoughts, calls tools, sees results, and keeps going until done.
That works well for simple problems, but falls short when things get more complex — either because the task is too long to reason about in one go, or because it benefits from breaking down into subcomponents.
That’s why I started looking at more advanced setups. Claude Code stood out — a CLI-based coding agent from Anthropic. It doesn’t just call tools — it appears to coordinate nested tasks, delegate subproblems, and manage state across toolchains. Watching it in action, it clearly uses some kind of hierarchical architecture, with a parent agent spinning off subtasks that are handled independently and reported back.
This post is my attempt to recreate something like that: a multi-agent system where a top-level orchestrator can delegate to stateless child agents with their own tools and logic.
How the Architecture Works
Let me jump ahead and show you where I landed, and how it works.
Agent Architecture

At a high level, it works like this:
The user passes in some input, like ‘build my schedule’
The OrchestratorAgent receives this, and recursively does one of three things (Direct, Delegate, Respond)
Direct: executes tools directly for simple tasks
Delegate: for more complex tasks, it delegates to a stateless child agent. From the perspective of the Orchestrator, these child agents are simply additional tools that it can call, but it passes in a prompt and any relevant state such as the schedule to build. The child agent itself can iteratively call tools and reason, before finally passing back a single response which is added to the log of the Orchestrator
Respond: once the Orchestrator decides that it is finished, or it needs more information from the user, it responds
Note that the tools available to the child agents are a subset of those available to the Orchestrator. This isn’t a requirement, but it’s what I’ve found to work best. Technically, the Orchestrator can do anything a child agent can, but there are multiple benefits to this structure (more on this below)
Here is it in action:
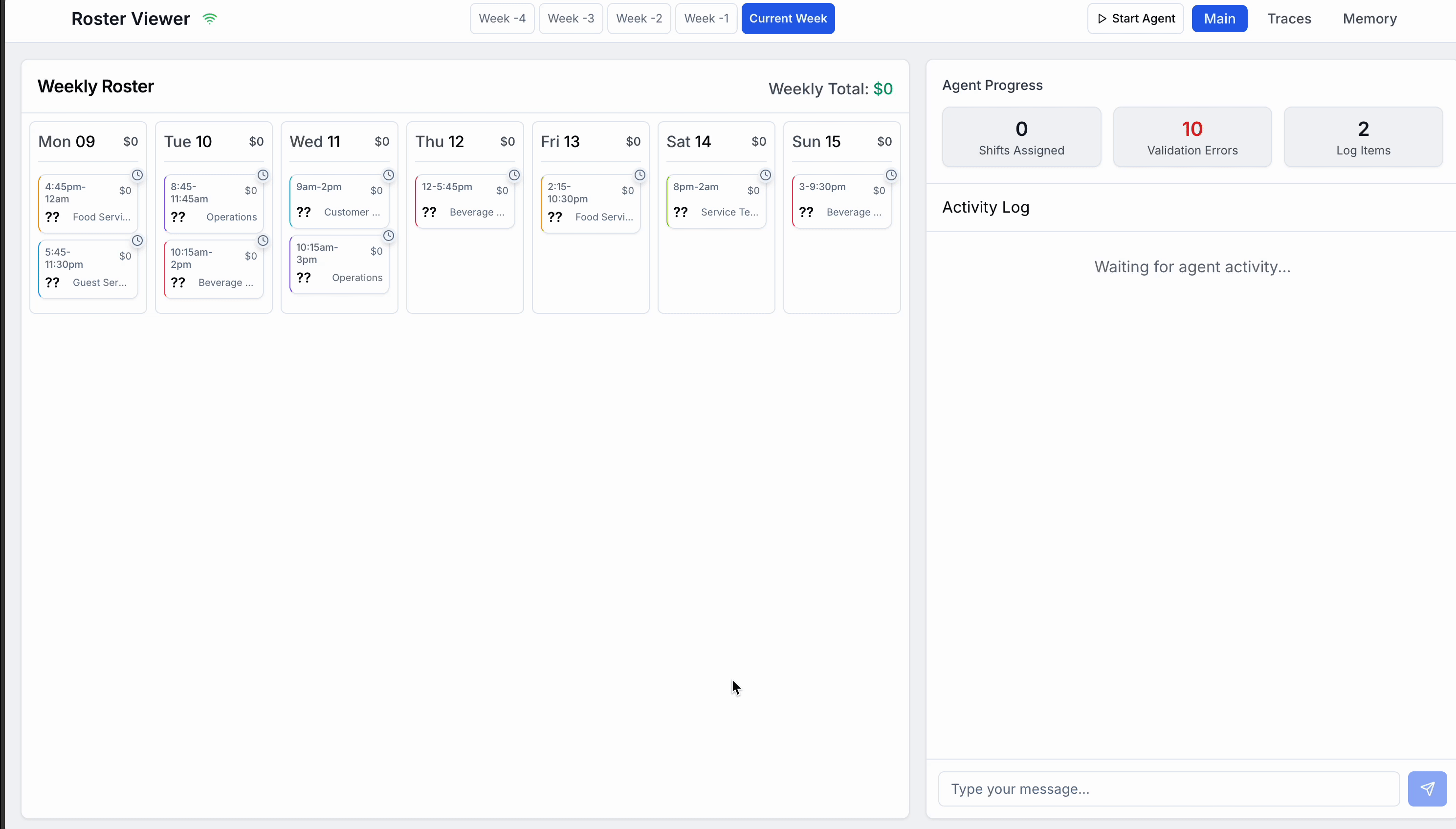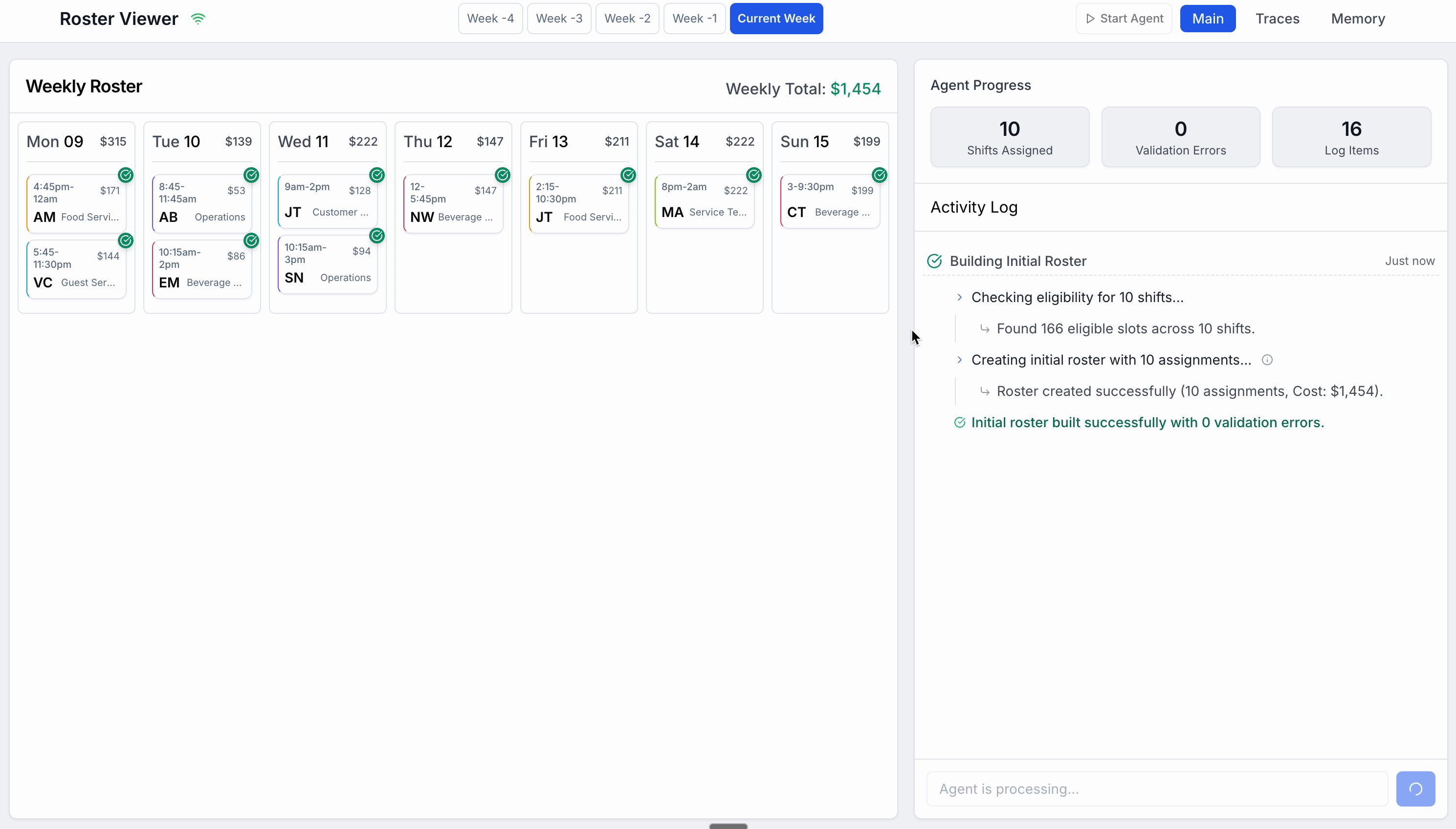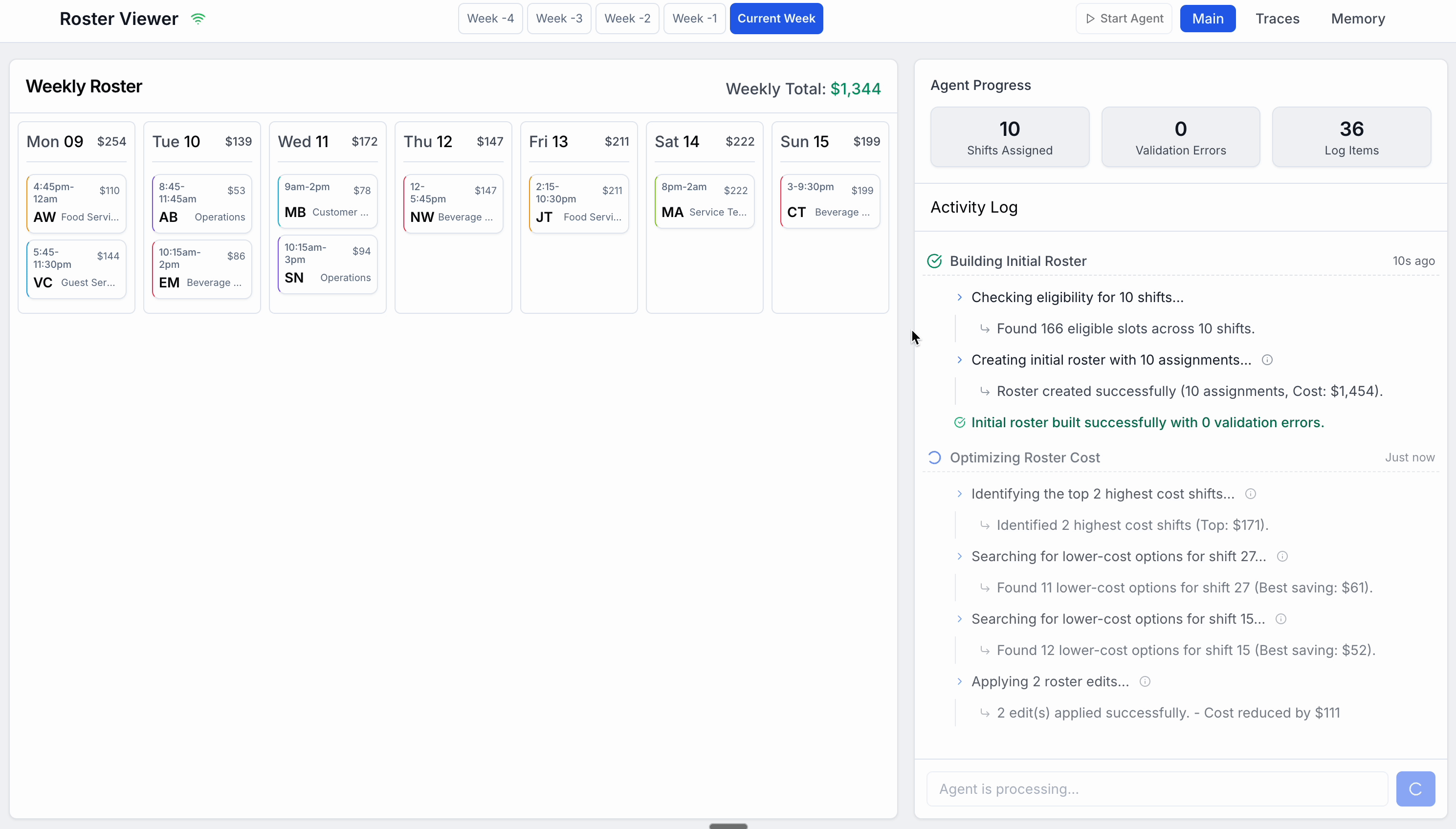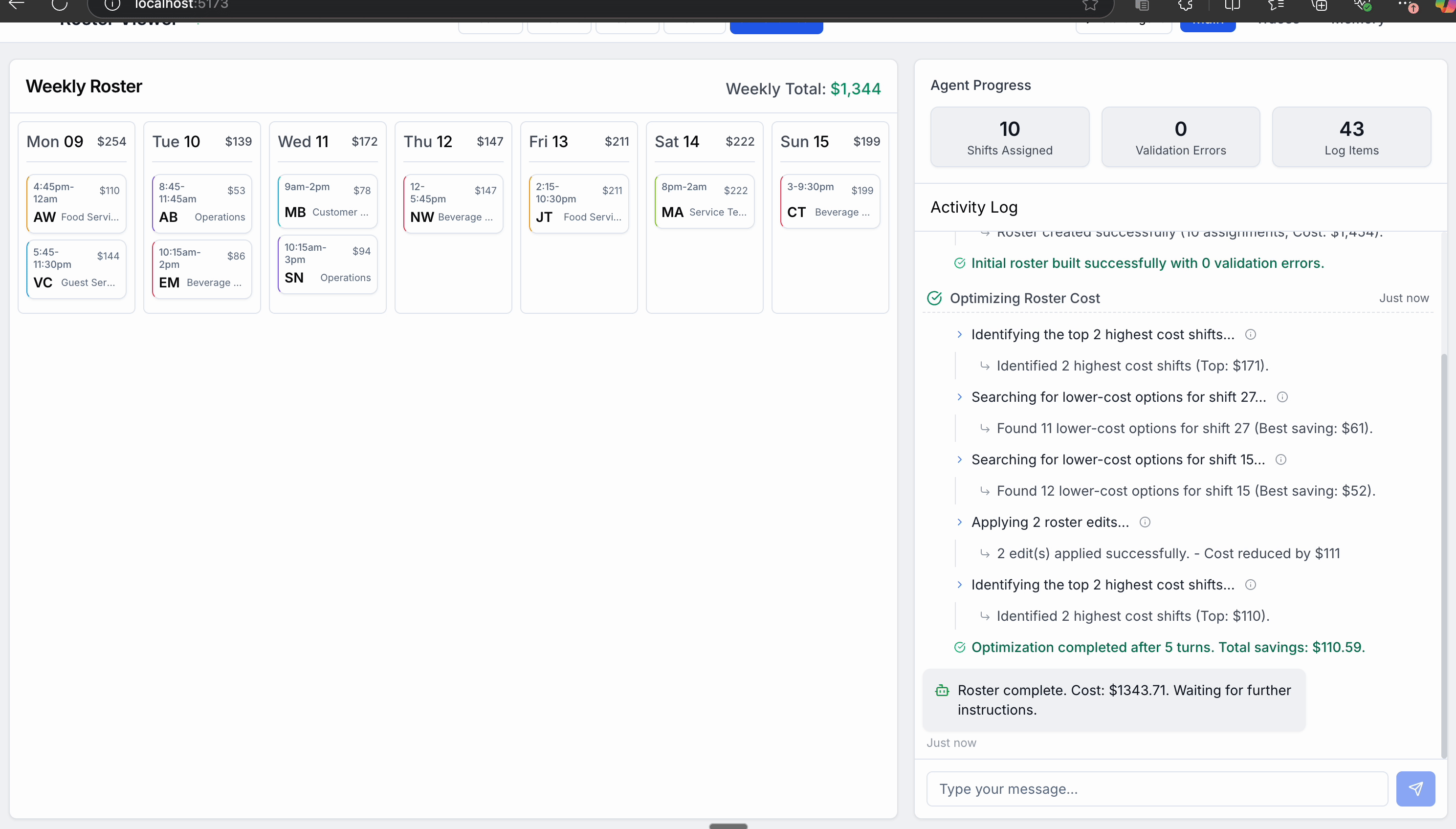
What you’re seeing here is that once I start the process, the OrchestratorAgent is handed a default task to build a schedule with 10 shifts distributed across the week. At a high level, it does the following:
It recognises this is a specialized task, and it hands off to the
BuildRosterAgentTool. It passes the Schedule object containing the shifts to fillBuildRosterAgentToolthenBegins by calling a tool which returns a list of eligible users for each shift taking into account their vacation and the teams they can work in (this is all static mock data I created, or I should say, an LLM created for me)
Then it calls the
create_rostertool and passes in it’s schedule. The return response confirms it is validSince it is valid, it returns a success message to the
OrchestratorAgent
The
OrchestratorAgentthen recognizes the schedule is built, and hands off to a specializedOptimizeCostAgentToolOptimizeCostAgentToolthenRuns a tool to find the most expensive shifts
Runs a tool to find lower cost alternatives
Makes some targeted edits to the schedule
Passes a success message back to OrchestratorAgent
OrchestratorAgentrecognises the task is complete, and messages the user to summarize
Here are the tools used across the agents:
create_roster: Generates a full schedule from eligible users. Returns a validation summary. (“Schedule” and “roster” used interchangeably.)edit_roster: Makes targeted edits to one or more shifts, using shift IDs and user IDs.get_eligible_users_for_shift: Returns available and qualified users for a given shift or set of shifts.find_shift: Looks up shifts by metadata (e.g. name, team, time). Used when the user refers to a shift conversationally — e.g., “Jon’s shift on Tuesday in the bar”get_highest_cost_shifts: Identifies the most expensive shifts in the current schedulefind_lower_cost_replacements: Finds cheaper eligible users for a given shift, often used to avoid overtime or penalty ratescreate_persistent_memory: Lets the Orchestrator store user-level preferences or recurring patterns — e.g., “Clara always works Sunday nights” — which can later be passed to scheduling agentsthink– a noop tool that lets the agent pause and reflect. Inspired by Anthropic’s work. This is the only tool the only the Orchestrator can access
(Child agents like BuildRosterAgentTool and OptimizeCostAgentTool also function as tools from the Orchestrator's perspective, but aren't listed here.)
Benefits of this approach
Compared to single-agent setups or simple prompt chaining, this architecture has a few key benefits:
Specialization: Each child agent has a focused prompt and toolset tailored to its subtask. This improves performance and reduces prompt complexity
Lower Token Usage: By delegating to stateless agents, you avoid accumulating long message histories. Child agents only return a summary, which keeps the Orchestrator's context light
Modularity: You can plug in new child agents (e.g., CostOptimizer, LeaveManager) without touching the logic of existing ones. This makes iteration safer
Model Efficiency: Stateless child agents can run on smaller, cheaper models when appropriate — saving cost without sacrificing output quality
Resilience at Scale: As I tested with larger schedules (up to ~500 shifts), the architecture scaled better than I expected. Both the Orchestrator and the child agents made use of the think() tool more often under load, which seemed to help with stability and recoverability when things went wrong
Below is one example of the robustness of this approach to using specialized agents. In this example, I used a smaller, cheaper and faster model for the BuildRosterAgentTool. You can see in the image below that it creates a roster with 13 errors, and immediately tries to edit those 13 shifts but it hallucinates some user_id’s. Because the error message is detailed, and because it has a detailed and specific prompt, and access to tools, it realized it should instead check which uses are eligible for the shifts with errors, and subsequently solves most of the errors in the following action, then continues to fix. My prompt doesn’t mention this specific pattern, but it gives the broad goal and provides detailed definitions of the tools available, so the model can work it out.
Practical tips for building Agents
Some of these are relatively obvious, but have been very helpful for me nonetheless:
Start simple and add complexity – if you have a complex task, break it down into pieces small enough that you can test the first one in a single prompt. If that works, expand the prompt, or add a tool, and then recursively continue this process. For example, I started by having claude write me some mock shifts, users and leave requests into json files, and then dropped those into a new instance and asked it to build a valid roster
Don’t use frameworks when you are starting – you’ll find many videos and blog posts about whether you should use Langchain or PydanticAI or CrewAI or [insert framework]. For production, those might be good ideas, but when you start, the abstractions just make it harder to debug what’s going on. It’s not that hard – especially with modern LLMs – to write the scaffolding yourself
Very early, spin up a simple UI or log to inspect your traces – by traces I mean the messages the LLM sends and receives, tool calls and tool results, etc. It has often been extremely useful to me to dig in and see exactly what the LLM sees to debug an issue, especially if you’re dynamically loading in data at runtime (example screenshot below of how I view my traces)
LLMs are pretty good at writing and iterating on prompts – if you’re not getting the agent or LLM to follow your instructions, try giving your prompt to a reasoning model (o3-mini, claude-thinking, gemini-2.5-pro, grok-3-thinking, r1) along with the logs from your agents outputs and explain that you want to optimize the prompt. If you iterate like this, models are quite good at progressively adjusting the prompt to minimize errors
Make sure your tool return values are detailed – remember to think carefully about what the model ‘sees’. After it calls a tool, it receives the response. The more detailed the response, the better it will subsequently navigate its next actions. For example, whenever the create_roster or edit_roster tools are called, I return the status of the entire roster including number of shifts, any shifts with validation errors (e.g., their assignment clashes with their vacation request). This let’s the model easily identify its next step
Example of my UI for inspecting model message traces

This is overkill for getting started, and you should start simple. This page shows the full history, with child agent message history indented for clarity, it is searchable, filterable by tool, agent or message type, and shows token usage for when you start looking to optimize costs.
What’s next
There’s still a lot to test. Some things I plan to explore next:
Scaling the system: How many child agents can the Orchestrator handle before performance drops?
Larger workloads: What’s the max roster size that still fits comfortably in memory and completes in reasonable time?
Cost vs complexity: How do inference costs scale as roster size increases?
Context compression: I’m experimenting with using a smaller model to periodically summarize the message history, to keep the Orchestrator coherent while reducing token load and extending the effective reasoning horizon
If you’re exploring similar questions or have ideas, I’d love to hear them.
Footnotes
1. For context, here are some of the constraints you need to adhere to when building schedules:
Hard constraints
Users are valid
Users can work in the teams they are rostered to
Users do not have clashing shifts
Users are not on vacation
Users are not unavailable (e.g., some employees are students, and cannot work during the day)
Soft constraints
Manager preferences (“I like having Gavin work the Saturday night shift behind the bar because he’s experienced”)
User preferences (“I prefer Friday nights off”)
Wage considerations – for a given schedule, many valid options will be undesirable due to costs. For example, in some jurisdictions, if an employee works two shifts less than X hours apart, they get paid at a higher rate. There are many versions of this to consider