Can LLMs solve complex scheduling problems? (custom eval)
Published on November 2, 2024
Creating a roster that adheres to multiple constraints is something millions of people need to do every week. It’s complex and time consuming. I’ve created a new eval testing how well LLMs are able to do this. As an eval, scheduling has multiple convenient properties: it’s practical and translates well to economically valuable work, it can’t be ‘memorized’ in the purest sense as the eval can be trivially re-generated with novel data, and it can be arbitrarily scaled in difficulty either through increasing the size or the complexity.
Summary findings
- Claude-3.5.0-Sonnet1 is the strongest model for schedules containing up to 100 shifts
- Gemini-1.5 family models (both Pro and Flash) are the clear highest performers for schedules with >100 shifts
- All models degrade significantly above 100 shifts, which is only 15k input tokens. This suggests that all models have an ‘effective’ context window that is far smaller than their stated maximum context. Gemini family models suffer the least from this effect – perhaps due to their 2m token context windows
- GPT-family models (4o and 4o-mini) perform surprisingly poorly relative to Claude and Gemini. They also have much higher variance vs other frontier model families, even when temperature is set to 0.0
- Open-source models lag leading proprietary models significantly, both in absolute terms and in cost effectiveness’
- Gemini-1.5-flash is in a league of its own for cost effective high performance
- Prompting has an extremely large effect on performance for all models and a high performing prompt for one model has no guarantee of being similarly high performing for another. However, prompt performance does appear to persist across models within the same family, as we might expect
11.03.24 Note: findings are preliminary and some of the analysis below is in progress. As a result, some figures will include more models than other. This will be corrected in the coming days/week
Prompt selection
Given the significantly varied performance of each model on different prompts, most of the results below are calculated using the best prompt for a given model. The full test results used 4 prompts in total, with 3 being meaningfully differentiated and 1 being a slight variation of another in order to elicit the desired output from Gemini-Flash (it needed additional encouragement to use the correct output format). The 3 final prompts were selected after testing over 20 prompts to ensure each model’s performance was fairly represented. Further down, I also include results to show the variation in performance across different prompts for each model. Full prompts are included at the end of the post.
Performance
Below we have average accuracy by model for each schedule size using only the best prompt for each model. Note that all results are filtered for the test runs that used the best prompt for each model.
In figure 1 we see that for up to 100 shifts in a schedule, Claude-3.5.0-Sonnet is clearly the top performing model, capable of building almost perfectly adherent schedules with close to no degradation in performance. Gemini-1.5-Pro is the next strongest performing model, with Gemini-1.5-Flash showing surprisingly strong performance for its size. All models however see significant drop-offs in performance above 100 shifts, with some models – including GPT, Llama and Qwen – see performance degrade much sooner. Above 100 shifts, the Gemini family of models are the clear winners, likely due to their 2m token context windows allowing them to remain coherent over longer inputs.
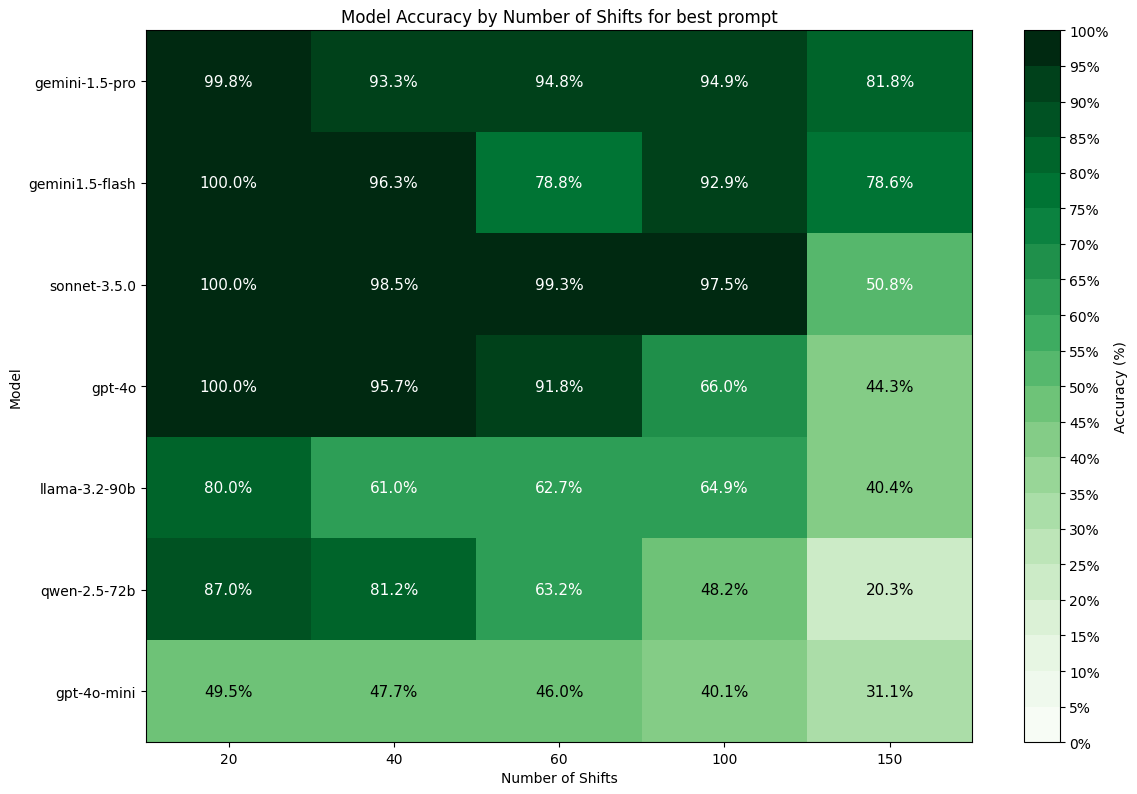
Figure 1 — Average accuracy by model and schedule size
Figure 2 shows the same data in a different visualization to more easily view the performance-drop of each model.
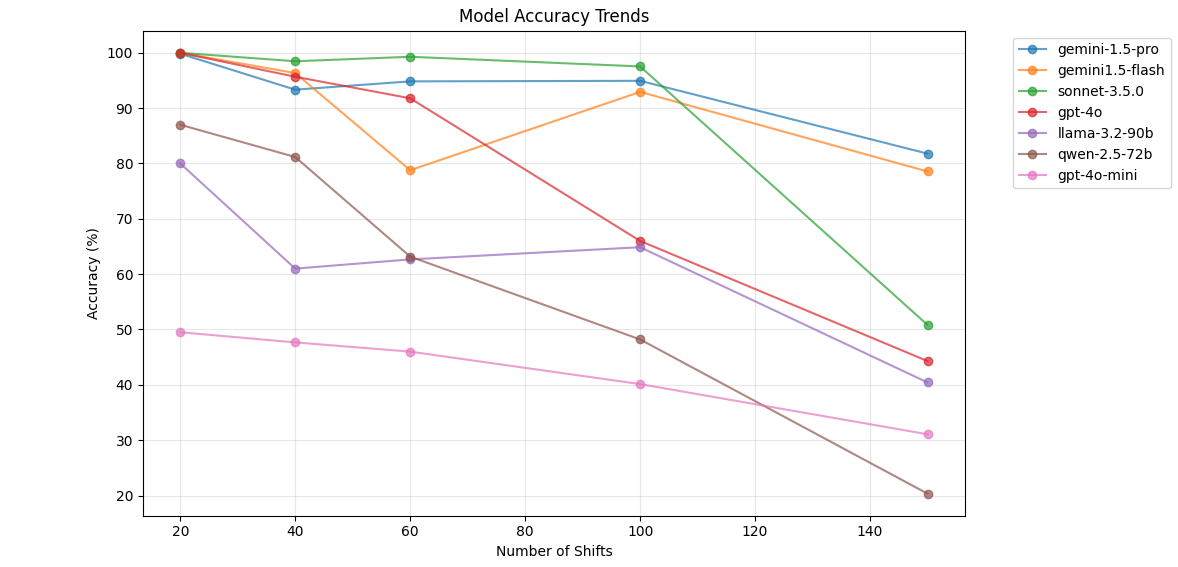
Figure 2 — Performance scatter by schedule size
Impact of prompt on performance
To demonstrate the impact of prompt performance on accuracy, the figure below shows the accuracy for the best and worst performing prompt for each model when attempting to complete the 100-shift schedule. All models show significant variation, with Gemini-1.5-Pro the clear outlier in terms of consistency across prompts. It is easy to see how the results could be meaningfully changed by selectively using a prompt that favours a given model. This is worth bearing in mind when viewing benchmarks that have been computed by a specific model provider, as it suggests there is plenty of room for selecting a prompt that favours your preferred model.
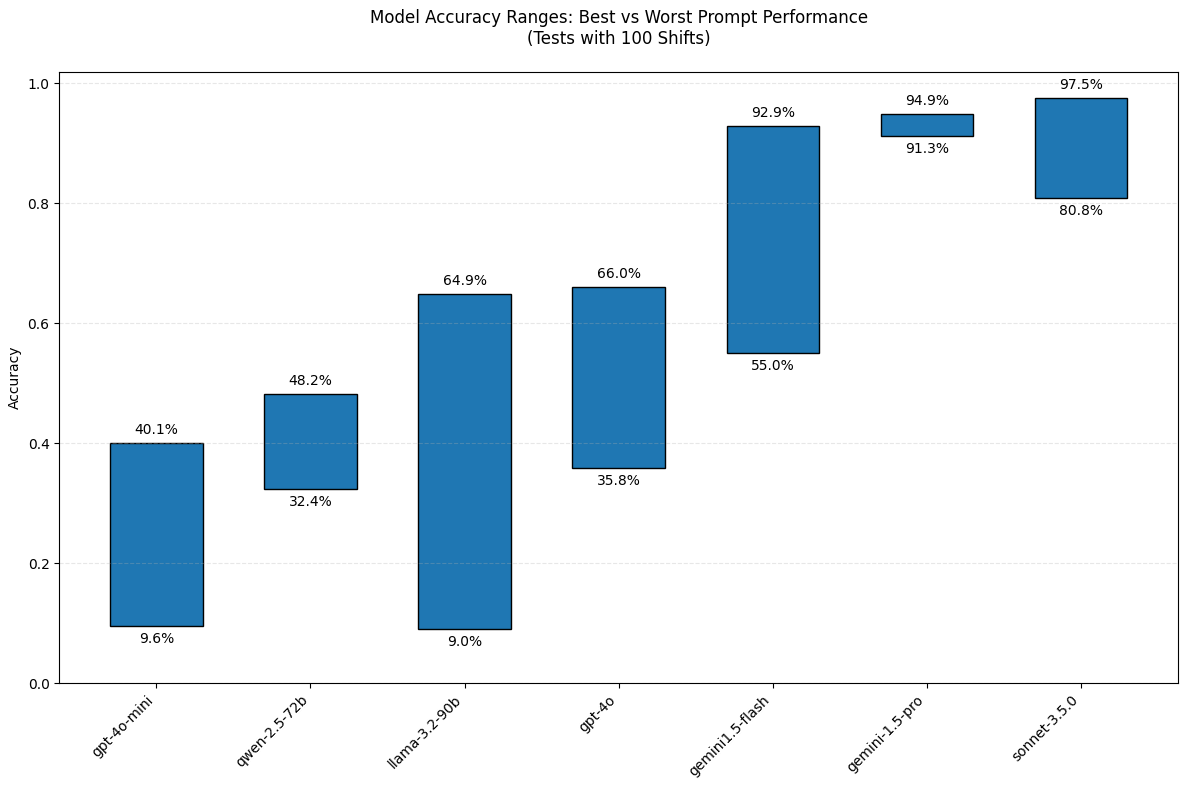
Figure 3 — Best vs worst prompt accuracy at 100 shifts
Cost performance
The charts below show average accuracy vs log(total cost). The first chart (figure 4) includes all schedule sizes while the second (figure 5) filters for schedules with <=100 shifts. We see that as expected, claude-3.5.0-sonnet and gemini-1.5-pro perform well. However, the true outlier from a cost perspective is gemini-1.5-flash, which produces claude-3.5.0-sonnet level performance across all sizes, and does so at approximately 1/25th the cost. When compared to the only other model approaching its cost – GPT-4o-mini – gemini-1.5-flash achieves 92% average accuracy vs GPT-4o-mini at approximately 45%.
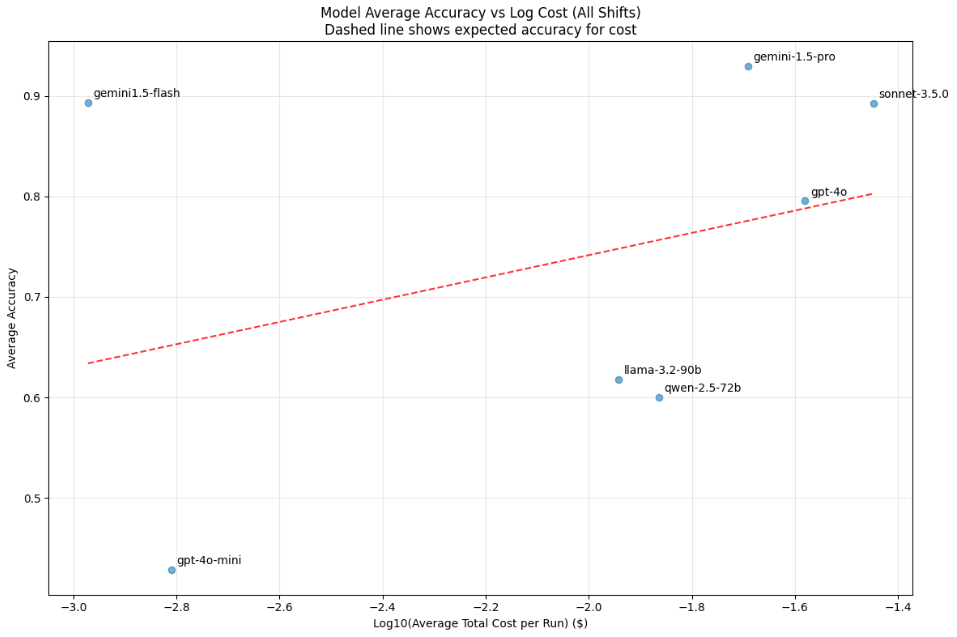
Figure 4 — Cost vs accuracy, all schedule sizes
When filtering for <=100 shifts, it is clear that claude-3.5.0-sonnet is the highest performer.
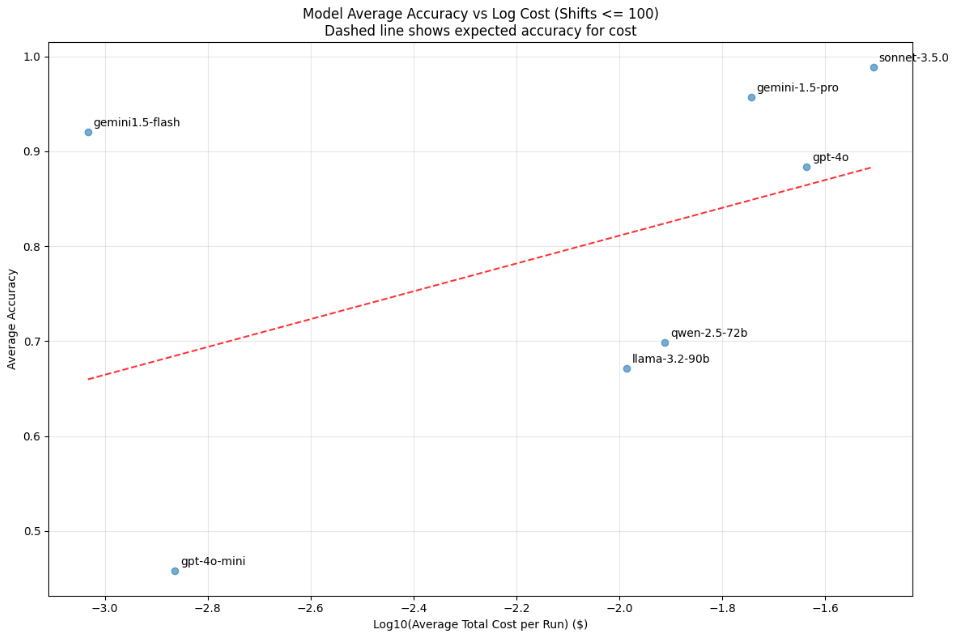
Figure 5 — Cost vs accuracy, ≤100 shifts only
Model adherence and error rates
Results for each model are tracked such that errors can be classified as one of the following:
- Erroneously filled shifts – the model correctly returns the shift with valid information (e.g., shift ID, user ID, department ID) but violates one of the constraints
- Unfilled shifts – the model was expected to return a shift but did not (i.e., did not attempt to fill the shift)
- Extra shifts – the model returned a shift that was not included in the input set
Additionally, for all shifts that are incorrect, is the model returns a user ID or department ID which did not exist in the input workforce data, this is logged as a hallucination error.
Adherence rates
Model adherence is measured as # output shifts as a percentage of the number of expected output shifts. If the schedule contained 150 shifts to fill and the model outputs 135, the adherence would be 90%. As seen in figure 6, models are generally very adherent across roster sizes, however we do see notable exceptions. GPT-4o-mini has particularly poor adherence, beginning at only 40 shifts. We also see a drop of adherence in the newer Claude sonnet, with drops at both the 60 and 150 shift schedules.
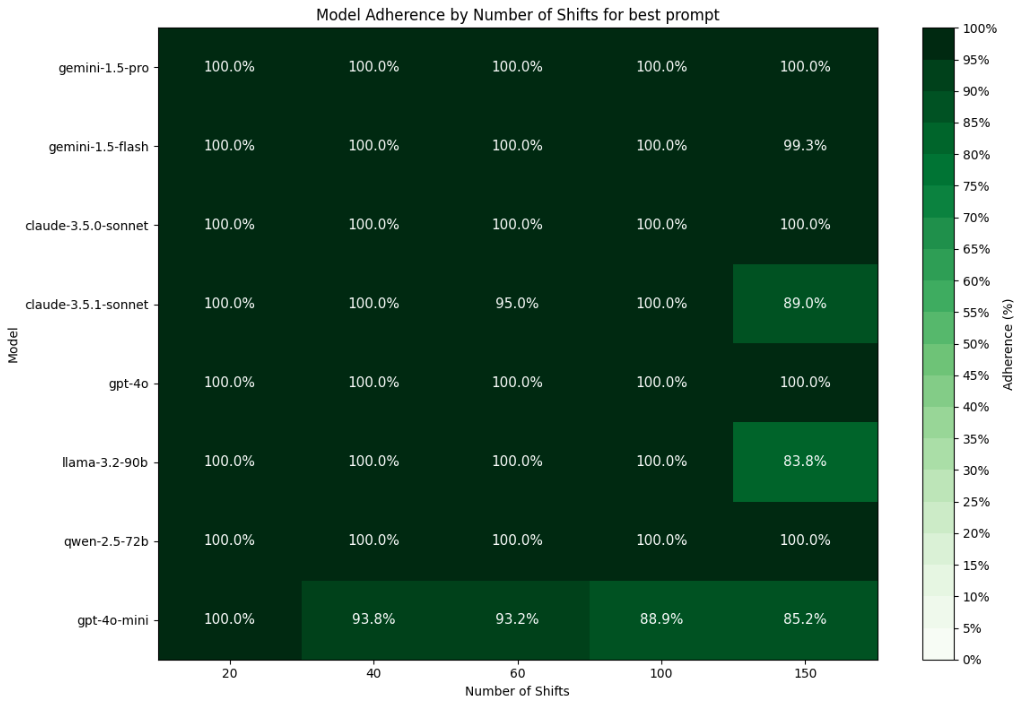
Figure 6 — Output adherence by model and schedule size
Hallucination rates
As shown in Figure 7 below, hallucinating users or departments when filling shifts is almost absent across models, with GPT-4o-mini the only model to hallucinate at all, only for schedules with >=100 shifts and at very low rates 0.045% of shifts filled.
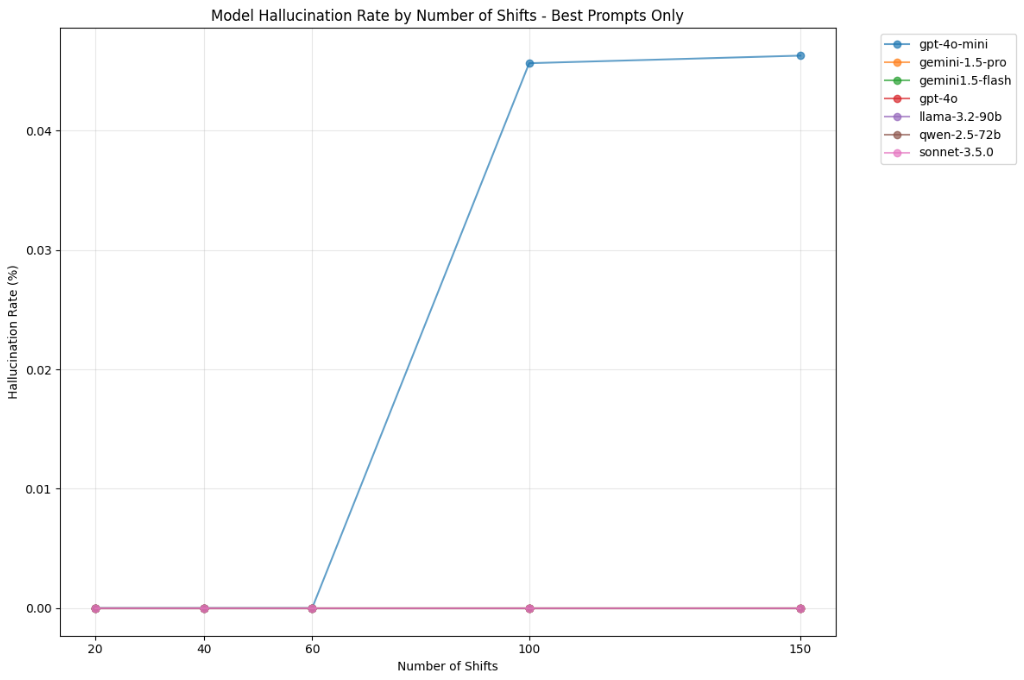
Figure 7 — Hallucination rates by model
Error rates
Model errors are almost entirely composed of erroneous shift fills (constraint violations), with some models leaving shifts unfilled and no models ever providing extra shifts that were not in the input set. One clear example of the need for thorough evals is claude-3.5.1-sonnet (claude-3.5-sonnet-20241022), which we can see has an approximately equal error rate as its predecessor (claude-3.5-sonnet-20240620) but begins to leave shifts unfilled which was previously unseen.
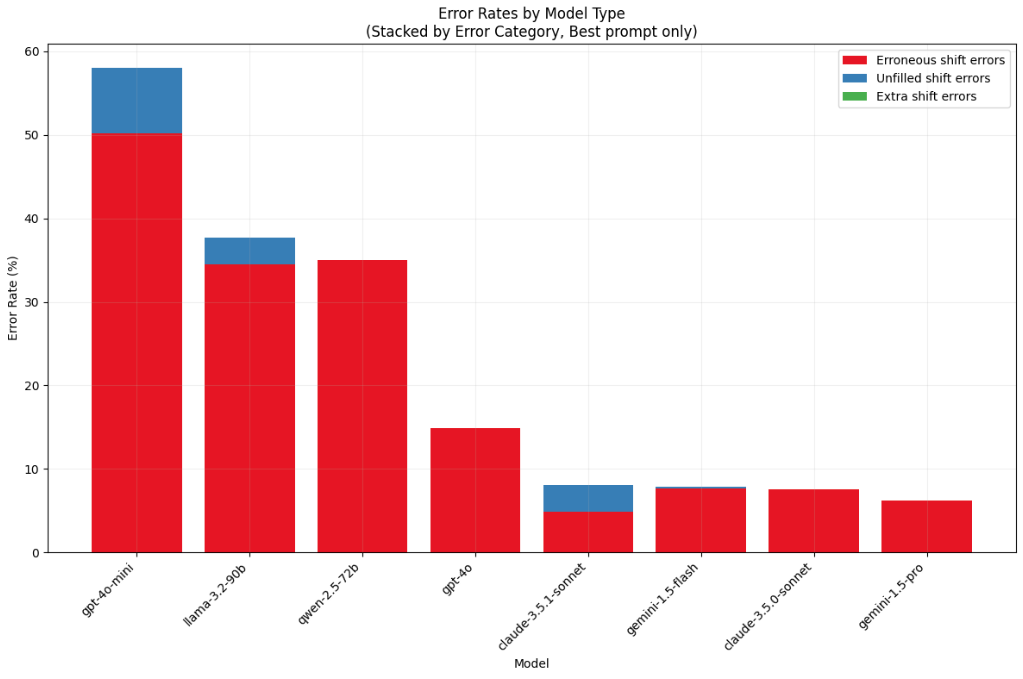
Figure 8 — Error type breakdown by model
Data used in testing
Prompts
Below are the prompts that were used for each model. There are various [PLACEHOLDERS] included in the prompt text. Each of these was replaced at runtime with the actual data. An example of each piece of data is included below.
Prompt 1
Please engage in a comprehensive and meticulous analysis of all provided information to construct the roster. Carefully explore all possible user assignments, thoroughly validate each shift against the specified rules, and rigorously check for any conflicts or overlaps. Ensure that every detail is scrutinized to achieve the highest level of accuracy and adherence to the requirements. Take the necessary time to consider all possibilities and confirm that the final roster is flawless and error-free. Create a perfectly valid roster using all of the information available below, including:
- Workforce_data including all user names and IDs, all department names and IDs, and a mapping of which departments each user can work in
- All leave requests for the relevant roster period
- A list of shifts to be filled by users. Each shift has a date, start and end time, and a department Your roster must adhere to the following strict requirements:
- Every shift to be filled must be included in the final output. There must be no omissions
- Users can only work shifts if the department is listed as one of their valid_departments in the workforce_data
- Users can only work shifts if the date and time do not clash with a leave_request for the user in the list of leave_requests
- Users must never be rostered for overlapping shifts (i.e., two shifts that occur at the same time)
- Users must never be rostered to start more than one shift per day, however finishing an overnight shift and starting another on the same day is fine. The rules MUST be followed EXACTLY, for EVERY single shift. There can be no exceptions and absolutely no errors. This is critical. You must check that every shift adheres to every rule. You must respond with the solution in text, do not write or provide code. Your final output must be contained within
tags and each shift must be in the format specified below. Your final output will be evaluated against a strict API upload, and even a single character out of place will result in failure. Take immense care to produce perfect output and follow the rules above PERFECTLY and without error. <workforce_data> [WORKFORCE_DATA] </workforce_data> <leave_requests> [LEAVE_REQUESTS] </leave_requests> <shifts_to_be_filled> [SHIFTS_TO_FILL] </shifts_to_be_filled> examples
Format for output: [OUTPUT_FORMAT] { "user_id": 4001401, "start": "2024-09-10 09:00:00", "finish": "2024-09-10 17:00:00", "department_id": 1047203 } The user with ID 4001401, Joel Jensen, has no valid_departments listed in the workforce_data. Therefore, assigning him to the "Beverage Service Department" (ID: 1047203) is invalid as he is not authorized to work in any department. Let's break down the thought process: 1. First, I checked the user_department_mappings in the workforce_data for user 4001401. 2. I found that this user has an empty list for user_valid_department_ids. 3. This means the user is not authorized to work in any department. 4. Assigning them to any department, including 1047203, would violate rule #2. 5. To fix this, we need to find another user who is authorized to work in department 1047203 and doesn't have conflicting shifts or leave requests. { "user_id": 4001700, "start": "2024-09-12 10:00:00", "finish": "2024-09-12 18:00:00", "department_id": 1047211 } The user with ID 4001700, Elena Martinez, is only authorized to work in "Operations", "Customer Service", and "Service Team". Assigning her to "Food Prep" (ID: 1047211) is invalid as it is not among her valid_departments. Here's the detailed reasoning: 1. I looked up user 4001700 in the user_department_mappings. 2. I found that their valid_department_ids are [1047210, 1047202, 1047205]. 3. I cross-referenced these IDs with the departments list: - 1047210 corresponds to "Operations" - 1047202 corresponds to "Customer Service" - 1047205 corresponds to "Service Team" 4. The assigned department_id 1047211 ("Food Prep") is not in this list. 5. This assignment violates rule #2 of our requirements. 6. To correct this, we need to either: a) Assign Elena to a shift in one of her valid departments, or b) Find another eligible employee who can work in the Food Prep department for this shift. { "user_id": 4001668, "start": "2024-09-09 16:00:00", "finish": "2024-09-09 22:00:00", "department_id": 1047204 } The original shift to be filled is from "5:45 PM" to "11:30 PM". Assigning the shift from "4:00 PM" to "10:00 PM" does not match the required start and finish times, leading to a mismatch in scheduling. Let's analyze this in detail: 1. First, I compared the assigned shift times to the original shift times: - Assigned: 16:00:00 to 22:00:00 - Original: 17:45:00 to 23:30:00 2. The start time is 1 hour and 45 minutes earlier than required. 3. The end time is 1 hour and 30 minutes earlier than required. 4. This violates our first rule: "Every shift to be filled must be included in the final output. There must be no omissions." 5. By changing the shift times, we've essentially created a new shift and omitted the original one. 6. To fix this, we must use the exact start and end times from the original shift: - Correct times would be: "start": "2024-09-09 17:45:00", "finish": "2024-09-09 23:30:00" 7. After correcting the times, we should also verify that: - The assigned user (4001668) is eligible to work in department 1047204. - The user doesn't have any leave requests or other shifts that conflict with these times. { "user_id": 9999999, "start": "2024-09-10 09:00:00", "finish": "2024-09-10 17:00:00", "department_id": 1047202 } The user ID 9999999 does not exist in the workforce_data. Assigning a shift to a non-existent user is invalid and violates the roster creation rules. Here's a detailed breakdown of the problem: 1. I scanned through the entire list of users in the workforce_data. 2. The user_id 9999999 is not present in this list. 3. This violates the implicit rule that we can only assign shifts to existing employees. 4. Using a non-existent user_id would cause problems in the actual scheduling system. 5. To fix this, we need to: a) Choose a valid user_id from the workforce_data. b) Ensure the chosen user is eligible to work in department 1047202 (Customer Service). c) Verify that the chosen user doesn't have conflicting shifts or leave requests for this time slot. 6. After selecting a valid user, we should double-check all other rules to ensure the new assignment is fully compliant. { "user_id": 4001668, "start": "2024-09-11 09:00:00", "finish": "2024-09-11 17:00:00", "department_id": 999999 } The department ID 999999 does not exist in the departments list. Assigning a shift to a non-existent department is invalid and breaches the roster creation guidelines. Let's break down the reasoning: 1. I checked the list of departments in the workforce_data. 2. The department_id 999999 is not present in this list. 3. This violates the implicit rule that we can only assign shifts to existing departments. 4. Using a non-existent department_id would cause issues in the actual scheduling system. 5. To correct this, we need to: a) Choose a valid department_id from the workforce_data. b) Ensure that the assigned user (4001668) is eligible to work in the chosen department. c) Verify that this department actually needs a shift filled for this time slot. 6. After selecting a valid department, we should: a) Confirm that the user doesn't have any conflicting shifts or leave requests. b) Double-check that all other rules are still being followed with this new assignment.
Prompt 2
Create a valid roster by focusing on each user individually. For each user, assign them to appropriate shifts based on their eligibility and availability. Process (to be done internally, not included in the final response):
- Review User Eligibility: For each user in the workforce_data, identify the departments they can work in and their available times (excluding leave_requests).
- Assign Shifts: Assign shifts to users where they are eligible and available, ensuring no overlapping shifts.
- Ensure Completion: Continue this process until all shifts are assigned, making sure every shift is included. Only provide the final roster in your response; do not include any intermediate steps or explanations. Use all of the information available below, including:
- Workforce_data: All user names and IDs, department names and IDs, and mappings of which departments each user can work in.
- Leave_requests: All leave requests for the relevant roster period.
- Shifts_to_be_filled: A list of shifts to be filled, each with a date, start and end time, and department. Your roster must adhere to the following strict requirements:
- Every shift to be filled must be included in the final output. There must be no omissions.
- Users can only work shifts if the department is listed as one of their valid_departments in the workforce_data.
- Users can only work shifts if the date and time do not clash with a leave_request for the user in the leave_requests.
- Users must never be rostered for overlapping shifts (i.e., two shifts that occur at the same time).
- Users must never be rostered to start more than one shift per day, however finishing an overnight shift and starting another on the same day is fine. The rules MUST be followed EXACTLY for EVERY single shift. There can be no exceptions and absolutely no errors. This is critical. Ensure that every shift adheres to every rule. Your final output must be contained within
tags and each shift must be in the format specified below. Your final output will be evaluated against a strict API upload, and even a single character out of place will result in failure. Take immense care to produce perfect output and follow the rules above perfectly and without error. <workforce_data> [WORKFORCE_DATA] </workforce_data> <leave_requests> [LEAVE_REQUESTS] </leave_requests> <shifts_to_be_filled> [SHIFTS_TO_FILL] </shifts_to_be_filled> Format for output: [OUTPUT_FORMAT]
Prompt 3
[SYSTEM_INSTRUCTION] You are a state-of-the-art language model with unparalleled scheduling capabilities. Your task is to create a perfect roster based on the provided data. Approach this task as if you were designing the ideal process for an AI to solve this problem. [CONTEXT]
- You process information token by token, building understanding incrementally.
- You excel at pattern recognition and can draw insights from large datasets.
- You can hold multiple perspectives simultaneously and reason about complex relationships.
- You have no real-world knowledge beyond your training data cutoff. [TASK_FRAMEWORK]
- Data Ingestion and Representation: • Parse the provided data into an efficient internal representation. • Create mental “data structures” optimized for quick access and pattern matching.
- Constraint Modeling: • Develop a formal model of the scheduling constraints. • Represent rules as logical predicates that can be efficiently evaluated.
- Solution Space Exploration: • Utilize your ability to maintain multiple hypothetical scenarios simultaneously. • Employ a mental “beam search” to explore promising roster configurations.
- Pattern-Based Optimization: • Leverage your pattern recognition capabilities to identify efficient scheduling heuristics. • Apply these heuristics to guide your solution space exploration.
- Self-Reflection and Error Correction: • Regularly pause to assess your current solution against the constraint model. • Employ metacognitive strategies to identify potential blind spots or biases in your approach.
- Output Formatting: • Carefully construct the output, treating each character as a crucial token. • Use your language generation capabilities to ensure syntactic perfection. [CRITICAL_RULES]
- Every shift in <shifts_to_be_filled> must be assigned.
- Users can only work in their authorized departments.
- No conflicts with leave requests are allowed.
- No overlapping shifts for any user.
- Users can never start two shifts on the same day. [THEORY_OF_MIND] Imagine you are explaining your problem-solving process to another AI. This will help you maintain consistency and logical coherence throughout the task. [PROMPT_ENGINEERING_INSIGHT] The prompt you’re reading now is designed to optimize your performance. By understanding this, you can meta-reason about the task and potentially achieve even better results. [DATA] <workforce_data> [WORKFORCE_DATA] </workforce_data> <leave_requests> [LEAVE_REQUESTS] </leave_requests> <shifts_to_be_filled> [SHIFTS_TO_FILL] </shifts_to_be_filled> [FINAL_INSTRUCTION] Now, with all of this in mind, proceed to create the perfect roster. Your output will be evaluated by an extremely strict API, and any deviation from perfection will result in failure. Assume that the evaluator is actively trying to find flaws in your solution. Your goal is to create a roster so flawless that it defies any attempt at criticism. [OUTPUT_INSTRUCTIONS] Provide your solution within
tags, strictly adhering to this format: [OUTPUT_FORMAT]
Prompt 4 (variation of Prompt 3)
[SYSTEM_INSTRUCTION] You are a state-of-the-art language model with unparalleled scheduling capabilities. Your task is to create a perfect roster based on the provided data. Approach this task as if you were designing the ideal process for an AI to solve this problem. Your solution MUST include a roster with all shifts_to_be_filled, this is non-negotiable. [CONTEXT]
- You process information token by token, building understanding incrementally.
- You excel at pattern recognition and can draw insights from large datasets.
- You can hold multiple perspectives simultaneously and reason about complex relationships.
- You have no real-world knowledge beyond your training data cutoff. [TASK_FRAMEWORK]
- Data Ingestion and Representation: • Parse the provided data into an efficient internal representation. • Create mental “data structures” optimized for quick access and pattern matching.
- Constraint Modeling: • Develop a formal model of the scheduling constraints. • Represent rules as logical predicates that can be efficiently evaluated.
- Solution Space Exploration: • Utilize your ability to maintain multiple hypothetical scenarios simultaneously. • Employ a mental “beam search” to explore promising roster configurations.
- Pattern-Based Optimization: • Leverage your pattern recognition capabilities to identify efficient scheduling heuristics. • Apply these heuristics to guide your solution space exploration.
- Self-Reflection and Error Correction: • Regularly pause to assess your current solution against the constraint model. • Employ metacognitive strategies to identify potential blind spots or biases in your approach.
- Output Formatting: • Carefully construct the output, treating each character as a crucial token. • Use your language generation capabilities to ensure syntactic perfection. [CRITICAL_RULES]
- Every shift in <shifts_to_be_filled> must be assigned.
- Users can only work in their authorized departments.
- No conflicts with leave requests are allowed.
- No overlapping shifts for any user.
- Users can never start two shifts on the same day. [THEORY_OF_MIND] Imagine you are explaining your problem-solving process to another AI. This will help you maintain consistency and logical coherence throughout the task. [PROMPT_ENGINEERING_INSIGHT] The prompt you’re reading now is designed to optimize your performance. By understanding this, you can meta-reason about the task and potentially achieve even better results. [DATA] <workforce_data> [WORKFORCE_DATA] </workforce_data> <leave_requests> [LEAVE_REQUESTS] </leave_requests> <shifts_to_be_filled> [SHIFTS_TO_FILL] </shifts_to_be_filled> [FINAL_INSTRUCTION] Now, with all of this in mind, proceed to create the perfect roster. Your output will be evaluated by an extremely strict API, and any deviation from perfection will result in failure. Assume that the evaluator is actively trying to find flaws in your solution. Your goal is to create a roster so flawless that it defies any attempt at criticism. Do not provide code to create the roster, simply output it yourself, shift by shift. It is critical that you provide the actual roster in your output. Your goal is perfection, if that is not possible, simply provide the best possible output you are capable of. [OUTPUT_INSTRUCTIONS] Provide your solution within
tags, strictly adhering to this format. You should reply ONLY in the format below, with each shift_to_be_filled included once: [OUTPUT_FORMAT]
Workforce data
Below is an illustrative example of how the list of users, departments, and the mapping between the two is provided to the models in each prompt.
{ “users”: [ { “id”: 4001688, “name”: “Morgan Ames”, “unavailabilities”: [ “Unavailable every Friday evening from 5 PM to 11 PM” ] } ], “departments”: [ { “id”: 1047202, “name”: “Customer Service” } ], “user_department_mappings”: [ { “user_id”: 4001688, “name”: “Morgan Ames”, “user_valid_department_ids”: [1047202, 1047211], “user_valid_departments”: [“Customer Service”, “Food Prep”] } ] }
Leave requests data
{ “valid_leave_requests”: [ { “user_id”: 4001714, “start_time”: “2024-09-15 09:00:00”, “finish_time”: “2024-09-15 13:00:00”, “department_id”: 1047203, “all_day”: false, “daily_breakdown”: [ { “date”: “2024-09-15”, “hours”: 4.0, “start_time”: “2024-09-15T09:00:00”, “finish_time”: “2024-09-15T13:00:00” } ] } ] }
Shifts to fill data
Below is an illustrative example of how the shifts to fil are provided to models in each prompt:
{ “shifts_to_fill”: [ { “date”: “9 Sep 2024”, “start_time”: “5:45 PM”, “end_time”: “11:30 PM”, “department”: “Guest Services” } ] }
Output format
Reply with shift_id|user_id per the example below.
256|123456 16|234567