Why isn’t AI diffusing faster?
Published on March 7, 2026
For the last three and a half years I’ve been the persistent (annoying?) friend telling everyone in my life that LLMs were going to be a bigger deal than they were expecting. Today this is definitely closer to the consensus view, especially if you’ve spent much time with a frontier model. That said, it’s probably still underappreciated. About six months ago I was having a discussion with a friend about enterprise AI adoption, and how we must be close to a capability level that would enable broad-scale deployment. We were debating deployment speed, and the likely limiting factors. One of my beliefs was that the models were good enough to start driving real productivity gains, but that access to talent and inertia were two of the limiting factors. Over the next few days as I kept thinking about this, I realized that my family runs a small ecommerce business, and that if I believed in automation for an enterprise, then automation for a small business should be much easier. Even better, the limiting factors should be less of a problem: I could build the tools myself, and changing a 2-person business should be much easier than a 20,000-person business. This is my six-month check-in to share what has worked and what hasn’t, and what I think it means for the diffusion of AI.
The business at hand is a girls clothing store based in Australia. It’s hosted on Shopify and otherwise uses a very simple tech stack: Gmail, Klaviyo, Facebook and Instagram. There are two employees. Most of the business involves buying and importing the products, running the online store, managing orders and returns, customer service, and acquiring new customers through various marketing channels. Very stock standard, and fairly digital, with the obvious exception of packing and sending orders.
Where to begin
I decided to start with something simple: business analysis. This is well and truly in-scope for frontier models, and a common pain point. Shopify makes it easy to see if revenue is up or down, but frankly their reporting is poor. It’s too confusing and makes it much too hard for a layperson to get the insights they need. I wanted something that could answer questions like:
- Why is revenue up this month? (price, volume, or mix)
- Which products, or types of products should we sell more, or less of
- Which products are overstocked, and how much should they be discounted
Business analysis
To begin, I built what I later turned into Rocky, a custom agent harness. This gave me a simple chat app with the ability to add custom tools, and importantly, was provider-agnostic. This was a non-negotiable for me given how often the leading model changes, and because I feel quite confident selecting the right model for a given task, at least for the moment.
Once this was built, and I could have a simple back-and-forth conversation, I began connecting tools. There are lengthy blog posts to be written on this alone, and how to balance the tradeoff between fewer, more flexible tools, and having more, more tightly scoped tools. The single best resource I found for this is Anthropic’s excellent post about writing effective tools for agents. In the end, I built a small number of tools:
- SQL tool for making read-only queries
- Code sandbox built with E2B so the agent can do more detailed analysis if it wants
- Shopify-specific utility tools like
topProductsandtopVariantswhich take a date range and run a pre-determined query for common user questions
This was straightforward to build, and as you’d likely expect, the models are excellent at this type of analysis. You do need to be careful to explain the quirks of your data, for example: my sales table has one line item for every product sold, so an order with multiple products has multiple rows. That means there is a column for the value of the product (product_price * qty) and another for the total order price. Because of non-product costs like tax and shipping, the sum of product_price for a given order does not equal the total order price. Most recently, models like GPT-5.2+ and Opus-4.6 tend to catch this even if you don’t tell them, but that’s not always the case. Giving the model access to a dedicated doc that explains the db schema and any notes like this makes it significantly more trustworthy.
As good as agents are at this type of work, the truth is that outside limited scenarios, it’s not hugely valuable. It definitely helps around the edges with things like working out that your white dresses are selling especially well this year, or that your free shipping threshold should be adjusted.
Customer service
Next, I decided to try and automate customer service. Unlike business intelligence, there is a clear path to creating value here by reducing costs and improving the quality of your customer service.
I’ve actually tried to build solutions here twice before. The first was a full-stack app that auth’d into Gmail and pulled in all threads to the app, and tried to use LLMs to draft responses. We never deployed it because my conclusion was that models were too brittle for the use case. In order to try and make it work you had to maintain an unreasonable number of custom prompts covering every scenario and edge case. In the end it proved too difficult for the capabilities at the time. This was in February of 2025, and OpenAI’s o1 was the smartest model available, but by today’s standards it was quite expensive.
The second attempt was the following month, and we did briefly deploy it. The solution is discussed here but essentially it was a sidebar within Gmail that held templates and used the context of a single thread to apply templates with minor customization. It worked initially but within a few weeks it was barely used. The main issue is that the prompts needed updating constantly, and for a busy business owner it was too time consuming to be worthwhile for the quality of response that GPT-4o was capable of.
Over the most recent Christmas break I tried a third time and it worked exceptionally well. Even better: it took no more than 3 days to build something worth using, and it’s been in use ever since, saving hours per day. This time, we had two significant breakthroughs. First, it was built on the same foundation as Rocky. Every new email triggers a fresh conversation, with the full thread context injected as the user message. By default, we use a custom system prompt for these conversations that is tailored to customer service. This meant a lot of the software building was already done since Rocky comes with LLM inference, persistence, monitoring and tool-use. For those conversations, we give the model some additional tools to search Gmail and save drafts.
The second breakthrough, which was likely even more important, was that instead of trying to hardcode behavior into prompts, we simply instruct the agent to begin by searching Gmail for the most recent similar cases, and use this to inform the response. Initially I didn’t realize what a huge improvement this would be but it quickly became clear. Not only do we not have to maintain prompts, but the model naturally picks up the style, tone and length of our responses. It also inherits our policies, like how we handle refunds or returns, and when we deviate from the default, because it can see how we’ve handled it in the past. Perhaps the greatest benefit of this approach is that in a way, it learns over time. I’m using the word loosely of course. But consider the following case: the agent searches for similar cases and drafts a response. The user decides the response was wrong and edits it before sending. Next time the agent faces that situation, or any that are similar, it follows the most recent behavior. This required no explicit intervention from the user.
The agent has some additional tools, like the ability to fetch all information from a specific product listing directly from Shopify. It can also query Ship24, an API for tracking shipments, the customer order history from Shopify, and it can read an internal spreadsheet we use to track returns. Between these, and our historical emails, the agent can answer essentially any customer query. It also provides a confidence score which we’ve found to be very well calibrated, since it knows when it couldn’t find similar scenarios, and flags as much.
It’s hard to describe what an unlock this was, especially after the initial attempts less than a year earlier which simply didn’t work. Today, this saves 1-3 hours per day, which is about 5-20% of total time for two people working on the business. It costs less than $10/day to run.
Inventory management
The most recent use case I attempted to address is deciding what, and how much to reorder. Like customer service, this is a clear case where improvements could be valuable: both in time saved, reduced costs from not overordering, and more revenue from not underordering. It also shares the helpful property of being entirely digital and benefiting from complex analysis that a business of this size usually wouldn’t get, of the type that frontier models are excellent at providing.
Historically this has been challenging, and like most small businesses, probably heavily underoptimized. The existing inventory management strategy could most accurately be characterized as “vibes based” with a little analytical rigor occasionally layered on top (e.g., last year I sold X of this dress, and sales are up about 10% this year, so we’ll reorder 1.1X).
My first experiment was asking an agent to construct a reorder for me using our harness. Since models can increasingly complete long-running tasks, and the harness provides access to all the required data, I thought this might work quite well. After many attempts it became clear this wouldn’t work. Model context windows are too limited, and model “laziness” was still a factor. Upon closer inspection, I found the model would make what I’d consider mistakes. They were mostly mistakes of internal inconsistency. It would forecast demand differently for two similar products, or it would use the business growth rate to gross up one product, and the product-specific growth rate for another. This might work if you have only a few products, but our business has hundreds of SKUs. However they also made mistakes I’d consider poor even for a junior analyst. Often I’d find that even frontier models would suggest that a product should be reordered because its sales had been climbing quickly without accounting for seasonality. This would manifest in it suggesting we made large reorders of Christmas dresses at the end of December, not realizing that demand was about to fall off a cliff.
Next I tried addressing this by having the model forecast for either one or a small number of products at a time, with a more clearly specified system prompt to try and standardize the methodology. This was an improvement, but there were new issues. First, the cost isn’t trivial. Even though model pricing is falling fast, and frontier model prices are extremely reasonable for their utility, 700 API calls to a model, each using tens or hundreds of thousands of input tokens, and thousands or tens of thousands of output tokens can add up quickly, especially while testing. If it was definitely going to work, it would be worthwhile, but I’d probably have to spend hundreds or thousands of dollars to figure that out. The second issue is explainability. Even if your forecast is produced with a superintelligent AI, the practical reality is that no business owner is going to trust it without verification. At least not at the beginning. And if the only way to unpick the rationale was to either read the reasoning traces, or trust that the AI-generated explanation was accurate, then you’ll probably never convince the average business owner to listen.
Eventually I landed on a mixed approach: start with a deterministic first pass, running a fairly simple algorithm to produce an approximate forecast to filter down to the products worth going deeper on. Second, for each of the filtered products, let an agent review and adjust as needed. This approach has many benefits. The cost is much lower, since usually only a small subset of products needs reordering. Second, by passing the agent the full input and output of the algorithm we ran, it could see the considerations we were implicitly baking in like seasonality, trading off business growth vs category growth vs product-specific growth. Third, by starting from a deterministic base, we could show the user the final output as a function of our algorithm, with the AI adjustment layered on top and clearly shown as such, giving them confidence that we’d considered everything. The image below shows what the user sees for each product, which includes an overall recommendation, along with current stock and recent sales. It also includes a breakdown showing how we landed on this number which includes:
- Sales from the same period last year
- Gross up to account for periods of low stock in the reference period
- Product-specific growth YTD
- Business growth YTD
- Existing stock, and expected sell-down prior to stock arrival
- AI adjustment
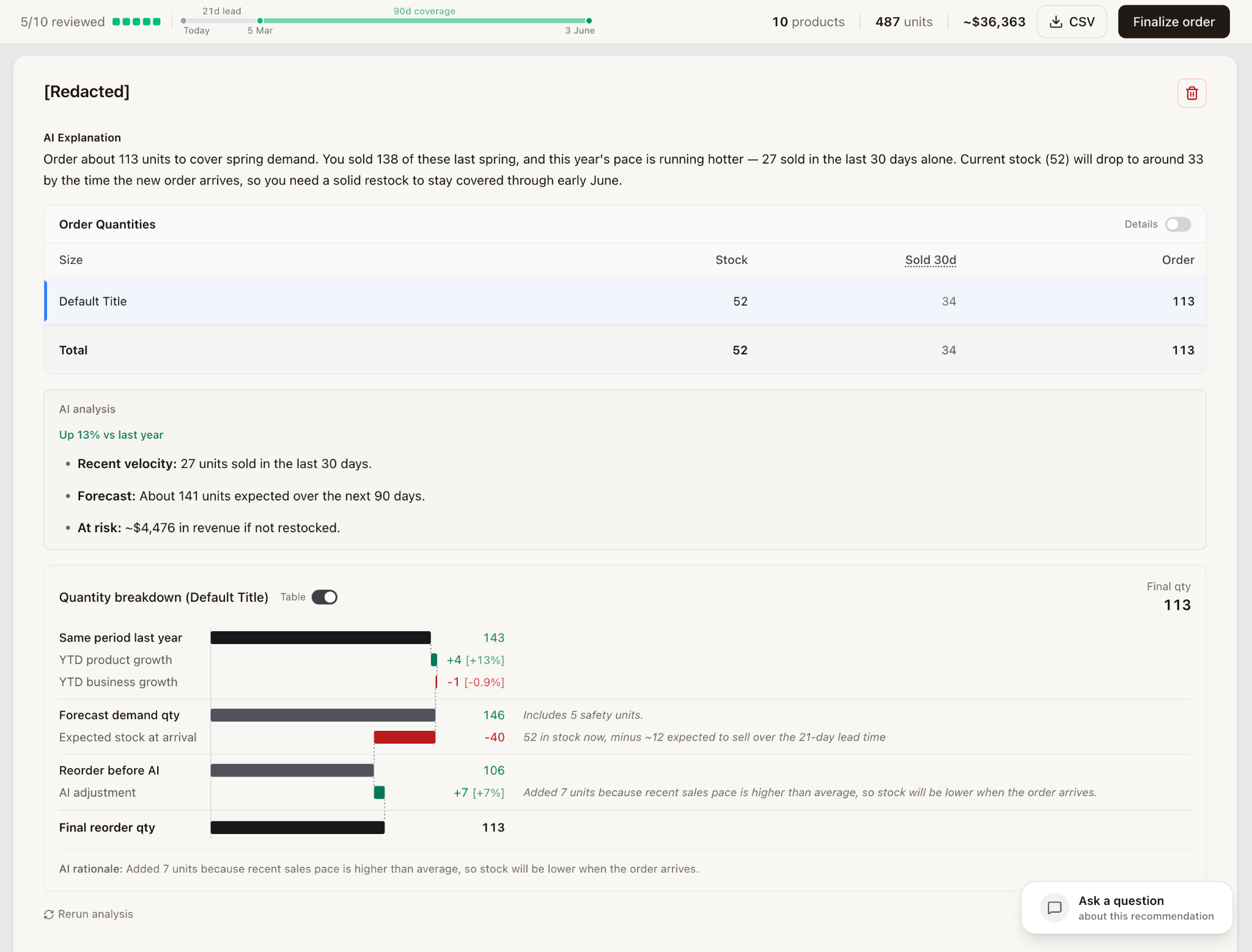
This turns out to be an excellent approach, as the agent gets the benefit of our existing knowledge with respect to how to reorder, and a framework within which to make changes. The benefit is clear here, where it would typically be quite hard to predetermine the exact right weighting of YTD vs more recent growth, or product vs business growth, but the agent is excellent at making these contextual decisions. In this case, it decides to increase our forecast, noting that the YTD growth number we’re using is hiding a recent acceleration, and effectively deciding to more heavily weigh recent growth, a very reasonable decision.
To test the reliability of our reordering agent, I built a small eval with a handful of scenarios that were adversarially corrupted. For example, I’d run the algorithm for forecasting but change the recommended order qty by increasingly difficult-to-catch amounts (anywhere from +/-50% to +/-5%). As a sign of AI progress, in December, no model consistently caught the more challenging cases. In early February, Opus-4.6 was reliably catching +/-10% issues. As of today (early March 2026) GPT-5.4 catches everything, every time, with medium reasoning.
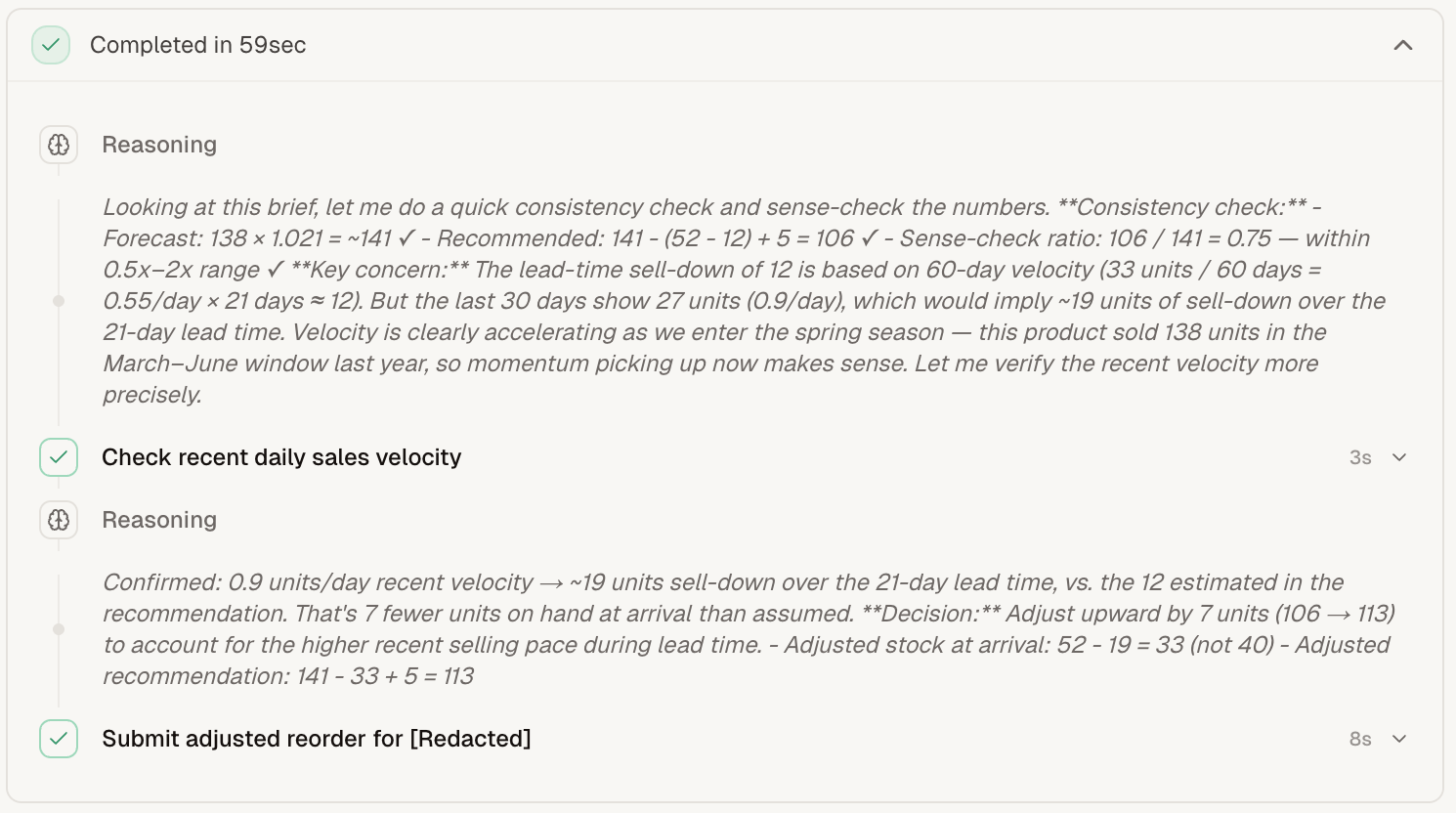
The inventory reorder flow is also built on Rocky, our existing harness. This pattern is extremely helpful, as it allows us to treat each product within a reorder as a separate conversation. This means the exact “thought process” — tool calls, reasoning, etc — is inspectable. It also means the user can ask follow-up questions, which are simply treated as another user turn in the existing conversation, so the agent can both explain further or make adjustments with full knowledge of what has been done previously. The image on the right shows exactly what this looks like in app.
As a final note, even though the reorder calculation is largely deterministic, it is worth noting that the best models helped significantly in tweaking this forecast methodology. For example, even recently I asked Gemini-3.1-Pro to review the approach and suggest improvements. It correctly identified and proposed a solution to the issue of floating holidays like Easter, which occur on different dates each year. The forecast now adjusts for these. So while the forecast itself may be largely deterministic, that is only possible at its current quality level as a result of AI proposing and implementing many of the features of this forecast.
Learnings
Reflecting on my progress, what have I learned? I think it falls into two categories: how to build these use cases, and why they’ve gotten so much more tractable recently.
How AI use cases want to be built
- Model everything as a conversation. Simply switching the system prompt and tool set of the agent is incredibly helpful. It makes it easy to reuse the same infrastructure for many problems, makes everything inspectable, and provides a very natural way to let the user interact and iterate on the agent’s work and collaborate on shared artifacts like a purchase order.
-
Build in ways that benefit from future model improvements. You need to think hard about how your solution will benefit from future model improvements. This has been a much-discussed topic for at least 2-3 years but it still doesn’t feel like we’ve completely figured out what this means. One of the things that makes this challenging is that before a model gets very good at something, it benefits significantly from you imposing as many methodological guardrails as you can, and from you manually deciding how to disaggregate the task into constituent pieces. The danger is that as soon as the model crosses some threshold of capability, these guardrails and steering are actively harmful to the outcome. As the models become better at instruction following this will continue to be the case. The more you predefine the process they must follow, the less you benefit from their alien thought process. Our customer service use case is well-suited for capability growth in the models that power it. Our reordering process is moderately so, but I suspect that in 6-12 months I would likely benefit from giving the models more freedom to forecast, even if by letting them rewrite the forecasting algorithm.
-
You need deep workflow knowledge. If you’re trying to replace or heavily augment a business process, you probably need either deep knowledge or need to be willing to sit and work with someone doing the job to catch these edge cases. Clearly the industry has caught onto this, as evidenced by the explosion of startups hiring FDEs. I suspect this is a function of trying to automate whole workflows. The previous generation of software only had to augment the workflow, and so could provide the user more sufficient degrees of freedom to adapt, but didn’t have to actively handle the edge cases. That’s no longer true if you’re trying to sell an outcome-based solution.
-
UI / UX matters more than you think for adoption. There are definitely lots of improvements to be made on the UI/UX side to enable collaborative work between agents and humans. I was surprised at how much time I spent simply trying to make this intuitive, and I’m sure there is lots of low-hanging fruit here. It definitely gave me a deeper appreciation for great designers.
- Build and maintain evals, especially for things the models can’t do. Unfortunately the hordes of people telling you to build evals are correct. It is especially important to build evals for things the models cannot do today. I often feel crazy trying to explain to a friend that they should retry their use case because of whatever model was released last week. GPT-5.4 was released three days ago, and has already noticeably improved the performance of all three of the use cases I’ve written about here. Not to mention that GPT-5.4-Pro is available and by all measures a meaningful jump again, but is currently limited to OpenAI’s $200 subscription, or available in the API at 12x the cost of GPT-5.4. Despite the plethora of publicly available evals, the value of building your own is probably going up, if only to indicate to you the gap between the models’ capabilities and how you’re currently using them.
Why did this suddenly get easier?
- Coding agents got really good. The only thing more amazing than the capabilities of current coding agents is their rate of improvement. It’s hard to overstate the extent to which I could never have built this even 6 months ago, let alone 12. I’m not even sure I could have done it three months ago, as that’s around when Opus-4.5 released. This has been a function of both better models and better harnesses, but mostly the former. Because my ability to write software is entirely limited by coding agents, I acutely feel the capability jumps of successive releases. From talking to my colleagues, I sometimes suspect this isn’t the case for them, largely because in many elements of the job their own ability exceeds that of the model. The one caveat I’ll offer is that software engineering is by no means “solved” or automated. I’m fairly sure we’ll get there, but it still takes a lot of human effort to build something useful.
- Browser use is helping close the loop. One very large recent unlock has been agents’ ability to use a browser well. This is in part because it helps “close the loop” and lets an agent test its changes and do QA in a way that wasn’t possible before, and in part because doing this allows the agent to run for many times longer without direction. If you haven’t, I recommend connecting Codex or Claude Code or OpenCode to something like Vercel’s Agent Browser.
- Terminal use has largely solved deployment for simple apps. Another recent unlock in agents’ ability to use a terminal extremely well has been for deploying code they write. This used to be one of the most painful parts of writing code, especially for non-engineers. Recently I’ve been able to deploy multiple apps to different hosting platforms like Railway, Render and Vercel, largely without having to actually open those platforms in a browser. Codex et al. are quite capable of both deploying, monitoring, and debugging your app anywhere that a CLI is available.
Takeaways
I feel very conflicted on the topic of AI diffusion. On the one hand, my first reflection is that doing this was honestly quite a bit harder than I expected. I didn’t expect automating a business to be easy, but I probably didn’t expect it to be as hard as it has been, and it’s by no means fully automated. If it takes this much work and iteration to handle the various edge cases and nuances of a business with two employees, then surely the complexity of doing anything remotely similar for a business with 2,000 employees would be multiple orders of magnitude harder. Larger businesses not only have a scaled-up version of this problem, but also the many incremental problems that come with scale: many more systems, security considerations, change management, etc.
On the other hand, much of what was difficult about this was the infrastructure. Building the software, connecting it reliably to various other systems, building reliable traceability, and a user interface that makes it both easy to use and to understand the actions taken by an agent so that human sign-off is easy to provide. This is an optimistic view, since I am not a particularly great software engineer, and so perhaps others, or future coding agents, will do this much faster. Software also scales quite well, and these problems don’t have to be solved independently for every business.
It seems to me that the models themselves are very clearly good enough for a large portion of white-collar work, and that the binding constraint is more about organizational readiness, which I take to include the ability to reorganize around new workflows, manage the change that comes with that, and unblock the many “papercuts” that make this difficult or impossible within the current business structure (e.g., letting various systems speak to one another).
The other very significant blocker to diffusion is access to talent. The nature of the models having gotten so much better in the last few months is that most people have no idea, nor anyone on their team with both the ability to use them to their fullest extent, and the organizational influence to try. You might ask why coding agents themselves don’t solve this today. They probably will in future, but they’re not there yet. They’re still much better as directed tools than independent agents. The other reason is stranger: the models powering these agents have training data cutoffs 6-12 months in the past and so have no real concept of what they’re capable of without a human setting the course. By definition this will somewhat resolve over time, but perhaps they’ll continue to have a lagging sense until we solve continual learning in some form.
If you’re doing this, where do you start?
Given my experience, if I was doing this for a large business, I’d start narrow. Pick the most narrowly defined workflow you can where automation would still add substantial value. I’d also be careful to pick an entire workflow. One trap I suspect many will fall into is automating a component of a workflow and then wondering why nothing has changed. The nature of organizations is that they’re full of bottlenecks, many implicit. Unless you target something end-to-end that can add value, you’ll likely find it impossible to point to any measurable improvement.
It’s also very helpful if you target a use case with some form of corpus to draw upon. One disadvantage of AI agents is their inability to learn and remember things. One advantage, however, is that they can read 6 months’ worth of examples and internalize the learnings for the length of their context window. The way to take advantage of this is to find use cases where much of the learning is encoded in the past examples, and where those past examples can be made available. Coding, via the codebase itself, customer support, via past interactions, invoice processing, via the historical mapping of invoices to cost categories, and writing contracts, via the corpus of previous contracts, are all examples of this. It is probably not a coincidence that these are among the use cases that are seeing fast adoption.
Most importantly, however you feel about the likelihood of continued progress, or the impact it will have, it is worth investing now to be prepared for whatever comes next. I’m personally not very convinced by expectations of large-scale unemployment or the like, but I do expect radical changes to how we work. If one of the main binding constraints is organizational readiness, and we expect this to become more true as models improve and talent adapts, then it pays all the more to invest now.